المجزئ الجغرافي: ضبط نموذج تجزئة أي شيء ذو التلقينات متعددة الوسائط لتجزئة البنية التحتية للتنقل ←
الملخص
يُقيد الأداء في مجال تجزئة الصور الجغرافية غالبًا بمحدودية بيانات التدريب ونقص القدرة على التعميم، لا سيما عند تجزئة البنية التحتية للمواصلات كالشوارع والأرصفة وممرات المشاة.
In geographical image segmentation, performance is often constrained by the limited availability of training data and a lack of generalizability, particularly for segmenting mobility infrastructure such as roads, sidewalks, and crosswalks.وقد أظهرت نماذج الرؤية الأساسية، مثل نموذج التجشئة المُدرّب مسبقًا على ملايين الصور الطبيعية، أداءً مذهلاً في التجزئة بدون مثال، مما يُقدّم حلاً واعدًا.
Vision foundation models like the Segment Anything Model (SAM), pre-trained on millions of natural images, have demonstrated impressive zero-shot segmentation performance, providing a potential solution. لكن، يُواجه نموذج التجشئة صعوبةً في التعامل مع الصور الجغرافية، كصور الأقمار الصناعية والصور الجوية، نظرًا لاقتصار تدريب النموذج على الصور الطبيعية، وتداخل ملامح الأجسام وقوامها من الفضاء مع محيطها.However, SAM struggles with geographical images, such as aerial and satellite imagery, due to its training being confined to natural images and the narrow features and textures of these objects blending into their surroundingsيقترح الباحثون في هذه الورقة لمعالجة هذه التحديات، نموذج التجشئة الجغرافي، كإطار عمل قائم على نموذج تجشئة بأداء محسن باستخدام تلقينات متعددة الوسائط مولدة تلقائياً.
To address these challenges, we propose Geographical SAM (GeoSAM), a SAM-based framework that fine-tunes SAM using automatically generated multi-modal prompts.يدمج نموذج التجشئة الجغرافي التلقينات النقطية من نموذج مُدرّب مسبقًا خاص لهذه المهمة كدليل بصري أساسي، مع تلقينات نصية مُولّدة بواسطة نموذج لغوي كبير كدليل دلالي ثانوي، مما يُمكّن النموذج من استيعاب كلٍ من البنية المكانية والمعنى السياقي بشكل أفضل.
Specifically, GeoSAM integrates point prompts from a pre-trained taskspecific model as primary visual guidance, and text prompts generated by a large language model as secondary semantic guidance, enabling the model to better capture both spatial structure and contextual meaning.يتفوق نموذج التجشئة الجغرافي على الأساليب الحالية في تجزئة بنية النقل التحتية في المناطق المألوفة وغير المألوفة بنسبة لا تقل عن 5% في مؤشر متوسط التقاطع على الاتحاد، مما يمثل قفزة نوعية في الاستفادة من النماذج الأساسية لتجزئة البنية التحتية للتنقل، بما في ذلك الطرق وممرات المشاة في الصور الجغرافية.
GeoSAM outperforms existing approaches for mobility infrastructure segmentation in both familiar and completely unseen regions by at least 5% in mIoU, representing a significant leap in leveraging foundation models to segment mobility infrastructure, including both road and pedestrian infrastructure in geographical images.تم نشر كود النموذج للعموم هنا.
The source code is publicly availableالمقدمة
ركزت الكثير من الأبحاث 1 2 3 4 5 على تجزئة البنية التحتية للطرق من الصور الجغرافية وصور الاستشعار عن بُعد، مثل الصور الجوية والفضائية، إلا أن البنية التحتية للمشاة، كالأرصفة وممرات عبور المشاة، لم تحظَ إلا باهتمام ضئيل نسبياً، رغم أهميتها في الحياة اليومية.
While a substantial amount of research [7, 43, 17, 28, 13] has focused on road infrastructure segmentation from geographical and remote sensing imagery like aerial and satellite images, pedestrian infrastructure, such as sidewalks or crosswalks, has received comparatively little attention, despite its importance in daily life.انصبّت الجهود البحثية تاريخياً على مساعدة السائقين في التنقل في الغالب بدلاً من مساعدة المشاة 6.
Historically, research efforts have predominantly focused on assisting drivers in navigation rather than pedestrians [^18].تستخدم دراسات إمكانية الوصول الحالية غالباً بيانات طرق مبسطة، ونعلم أن التجزئة الدقيقة لبنية المشاة التحتية تُسهم في الكشف بشكل أفضل عن الطرق والوجهات المُيسّرة، لا سيما للأشخاص ذوي الإعاقة.
Existing accessibility studies often use simplified road data, but accurate segmentation of pedestrian infrastructure can better reveal accessible routes and destinations, especially for people with disabilities.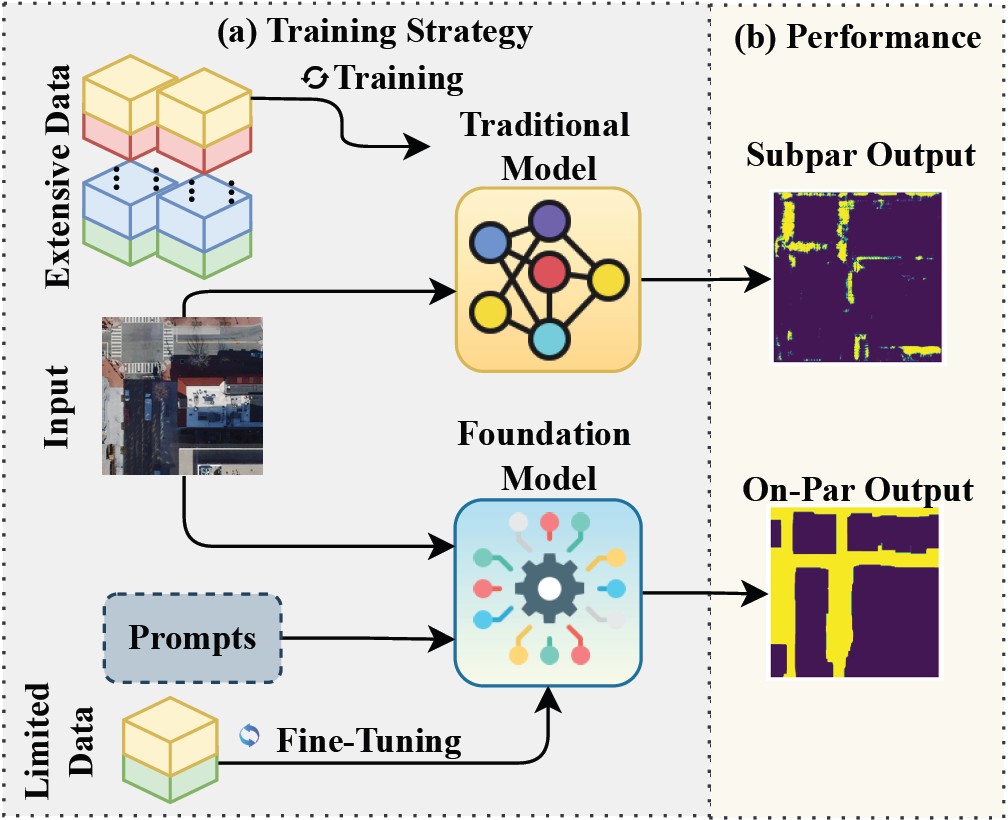
الشكل: 1 تجزئة البنية التحتية للتنقل: (أ) تحتاج النماذج التقليدية إلى مجموعات بيانات كبيرة خاصة بكل مهمة، (ب) وتواجه صعوبة في التعامل مع الكائنات الضيقة ذات النسيج المتشابه، مما ينتج عنه نتائج دون المستوى المطلوب.
Mobility infrastructure segmentation: (a) Traditional models need large task-specific datasets, (b) struggle with narrow, texture-similar objects, yielding subpar results.ويحقق ضبط نموذج أساسي قابل للتلقين باستخدام بيانات وتوجيهات محدودة أداءً مماثلاً.
Fine-tuning a promptable foundation model with limited data and prompts achieves on-par performance.اعتمدت تاريخياً تجزئة البنية التحتية للتنقل بشكل أساسي على النماذج التقليدية، بما في ذلك الشبكات الطي العصبية 7 8 9 10 ونماذج مُحوّل الرؤية 11 12.
Rooted in historical context, mobility infrastructure segmentation has predominantly relied on traditional models, including Convolutional Neural Networks (CNNs) [31, 45, 20, 27] and Vision Transformer (ViT) models [14, 11].تتطلب تلك النماذج عادةً مجموعات كبيرة من الصور المعنونة يدوياً للتدريب الخاص بكل مهمة 6 13، وهو أمرٌ غالبًا ما يكون ترفًا لهذه المهام، كما أنها غالبًا ما تكون شديدة الحساسية للتغيرات في البيانات.
These models typically require large collections of human-labeled data for task-specific training [18, 3], something that is oftentimes a luxury for these tasks, and are often too sensitive to changes in data.ولا يزال نقص مجموعات البيانات المعنونة بجودة عالية يمثل تحديًا كبيرًا، لا سيما في سياق البنية التحتية للتنقل، مما يحد من قابلية التوسع والتكيف مع المهام المتنوعة.
However, the scarcity of high-quality labeled datasets remains a major challenge, especially in the context of mobility infrastructure, limiting scalability and adaptability to diverse tasks.تفشل النماذج التقليدية غالبًا، عند تدريبها على مجموعات بيانات محدودة ومتجانسة (الشكل 1a)، في التمييز بين الفئات الدقيقة (مثل الأرصفة والطرق)، والتي تُظهر اختلافات بصرية دقيقة (مثل الحدود الرقيقة، والنسيج المتشابه، والحجب المتكرر) (الشكل 1b).
Traditional models, when trained on limited and homogeneous datasets(Figure 1a), often fail to distinguish fine-grained classes such as sidewalks and roads, which exhibit subtle visual differences like thin boundaries, similar textures, and frequent occlusions (Figure 1b).اوة على ذلك، فإن ما تعلمته تلك النماذج من تمثيلات للكائنات والأجسام عادةً ما تكون خاصة بمجال معين، ما يؤدي إلى ضعف التعميم عند استخدامها في مناطق غير مرئية أو مجموعات بيانات ذات خصائص بصرية مختلفة.
Moreover, their learned representations are typically domain-specific, resulting in poor generalization when deployed in unseen regions or datasets with different visual characteristics.وحتى التحولات الطفيفة في توزيع البيانات، مثل الانتقال من منطقة جغرافية إلى أخرى، غالبًا ما تؤدي إلى تدهور كبير في الأداء.
Even minor shifts in data distribution, such as moving from one geographic region to another, often lead to significant performance degradation.تُقدم - في المقابل - نماذج الرؤية الأساسية، المُدربة مسبقًا بشكل مستقل عن المهمة على توزيعات صور متنوعة وواسعة النطاق 14 15، بديلاً واعدًا بقدرة تعميم فائقة (عبر مجالات متنوعة).
In contrast, vision foundation models, pre-trained taskagnostically on large-scale and diverse image distributions [21, 26], offer a promising alternative with superior generalization ability across varying domains.تتكيف هذه النماذج مع المهام اللاحقة الجديدة (دون الحاجة إلى إعادة التدريب)، معتمدةً على توجيهات المستخدم للإرشاد السياقي.
These models adapt to new downstream tasks without re-training, relying on user-provided prompts for contextual guidance.استفاد الباحثون في هذه الورقة من نموذج التجشئة (تجزئة أي شيء) 14، وهو نموذج رؤية أساسي قابل للتوجيه، للتغلب على قيود الأساليب التقليدية وتمكين التجزئة الفعالة للبنية التحتية للتنقل، حتى مع البيانات المعنونة المحدودة وعبر مناطق جغرافية متنوعة.
In this work, we leverage the Segment Anything Model (SAM) [21], a promptable vision foundation model, to overcome the limitations of traditional approaches and enable effective segmentation of mobility infrastructure, even with limited labeled data and across geographically diverse regions.تتطلب الهياكل واسعة النطاق مكانيًا، كالشوارع والأرصفة، عادةً عدة محاولات متكررة لالتقاط امتدادها الكامل، على عكس الأجسام الصغيرة في الصور الطبيعية، حيث تكفي نقطة واحدة (مثلاً، على جسم حصان) للتجزئته.
However, unlike compact objects in natural images, where a single point (e.g., placed on a dog’s body) often suffices for segmentation, spatially extensive structures like roads and sidewalks usually require multiple iterative prompts to capture their full extent.هذه العملية مرهقة وعرضة للأخطاء غالباً، وحتى مع المحاولات المتعددة، سيواجه نموذج التجشئة بدون مثال صعوبة في مهام الاستشعار عن بعد نظراً لتدريبه المسبق على الصور الطبيعية، التي تفتقر إلى الهياكل الكبيرة ذات النسيج المتشابه الشائعة في البيانات الجغرافية 14.
This process is often exhaustive and error-prone, and even with multiple prompts, zero-shot SAM struggles in remote sensing tasks due to its pre-training on natural images, which lack the large, texture-similar structures common in geographical data [21].نستطيع مع ذلك تكييف قدرة نموذج التجشئة على تجزئة الصور الجغرافية من خلال ضبطه بدقة على بيانات محدودة (أسفل الشكل 1)، ما يسمح له بتعلم أنماط خاصة بالمجال والحفاظ على فعاليته في ظل تغيرات التوزيع المكاني.
Nonetheless, SAM’s general segmentation capability can be adapted to geographical imagery via fine-tuning on limited data (bottom of Figure 1), allowing it to learn domain-specific patterns and remain effective under regional distribution shifts.قدم الباحثون في هذه الورقة نموذج التجشئة الجغرافي بالاستفادة من تلك الميزة، وهو نموذج شامل مصمم لتجزئة البنية التحتية للتنقل من خلال تجزئة متعددة الفئات للطرق والنبية التحتية للمشاة.
Capitalizing on this strength, we introduce Geographical SAM (GeoSAM), an end-to-end model tailored for segmenting mobility infrastructure through multi-class segmentation of road and pedestrian infrastructure.يقترح الباحثون في هذه الورقة تقنية توليد النقاط الجغرافية لمعالجة التحديات السابقة، وهي تقنية تولد تلقينات نقطية آلياً للصور الجغرافية من نموذج مُدرَّب مسبقًا خاص بمجال الصور الجغرافي، وذلك لتوفير توجيه مكاني دقيق.
To address these challenges, we propose Geo-Point Generation (GPG), an automated prompt generation technique that generates point prompts for geographical images from a domain-specific pretrained model for precise spatial guidance.وتُكمَّل هذه التقنية بتلقينات نصية لتوضيح المعنى الدلالي وحل الغموض الكامن في التوجيه القائم على النقاط.
It is complemented by text prompts for semantic clarity to resolve ambiguities inherent in pointbased guidance.تلفت التلقينات النقطية تركيز النموذج على بكسلات مُحدَّدة، لكن غالباً ما ينتمي بكسل واحد على الصور إلى عدة كائنات.
Point prompts focus the model on specific pixels, but a single pixel can often belong to multiple objects.فتأتي التلقينات النصية، والتي تحتوي على معلومات دلالية حول صنف الكائن، لتقدم فهماً أوسع للكائن محل الاهتمام 16.
Text prompts, containing semantic information about the class, clarify the object of interest and provide a broader understanding [37].يضمن هذا التصميم المتكامل توجيهًا هندسيًا دقيقًا من التلقينات النقطية وفهمًا سياقيًا أوسع من التلقينات النصية، ما يُحسِّن دقة التجزئة.
This complementary design ensures precise geometrical guidance from point prompts and broader contextual understanding from text prompts, enhancing segmentation accuracy.تضبط التلقينات متعددة الوسائط نموذج التجشئة من خلال وحدة فك التشفير.
These multi-modal prompts fine-tune SAM through its lightweight decoder.قدم الباحثون في هذه الورقة المجشئ الجغرافي من خلال دمج الدقة المكانية (عبر التلقين النقطي على الصورة) والسياق المكاني (عبر التلقين النصي الذي يصف الكائن)، كنموذج التجشئة متكامل مُحسَّن لتجزئة الطرق والبنية التحتية للمشاة إلى فئات متعددة.
By integrating spatial precision with semantic context, we introduce Geographical SAM (GeoSAM), an end-to-end SAMbased model fine-tuned for multi-class segmentation of roads and pedestrian infrastructure.يتفوق المجشئ الجغرافي على الأساليب التقليدية القائمة على شبكات الطي العصبية 6 3 2، ليس فقط بتحسين دقة التجزئة، بل أيضًا بإظهار إمكانية دمج اللغة الطبيعية والتفاعل المرئي ضمن النماذج الأساسية للصور الجغرافية.
GeoSAM outperforms traditional CNNbased approaches [18, 17, 43], not only improving segmentation accuracy but also demonstrating the potential of combining natural language and visual interaction within foundation models for geographical imagery. تتلخص إسهامات الباحثون في ثلاثة جوانب: (1) الريادة في استخدام المجشئ لتجزئة البنية التحتية للتنقل إلى فئات متعددة، من خلال دمج التلقينات النقطية والنصية في الصور الجغرافية.(2) تقديم تقنيات ضبط النماذج وتوليد التلقينات تلقائيًا، والتي تجلب المعرفة المتخصصة من النماذج التقليدية إلى النماذج الأساسية عبر التلقينات متعددة الوسائط.
(2) We introduce fine-tuning and automated prompt generation techniques that inject domain knowledge from traditional models via multi-modal prompts.(3) إجراء تقييم شامل على مجموعات بيانات مدينتين، ما أظهر الأداء القوي لنموذج التجشئة الجغرافي وقابليته للتعميم عبر مواقع متنوعة.
(3) We conduct extensive evaluations on datasets from two cities, demonstrating GeoSAM’s strong performance and generalizability across diverse locations.المراجع
Footnotes
-
X. Chen, Q. Sun,W. Guo, C. Qiu, and A. Yu. Ga-net: A geometry prior assisted neural network for road extraction. International Journal of Applied Earth Observation and Geoinformation, 114:103004, 2022. ↩
-
L. Zhou, C. Zhang, and M. Wu. D-linknet: Linknet with pretrained encoder and dilated convolution for high resolution satellite imagery road extraction. In Proceedings of the IEEE conference on computer vision and pattern recognition workshops, pages 182–186, 2018. ↩ ↩2
-
C. Henry, S. M. Azimi, and N. Merkle. Road segmentation in sar satellite images with deep fully convolutional neural networks. IEEE Geoscience and Remote Sensing Letters, 15(12):1867–1871, 2018. ↩ ↩2
-
A. Saha. Conducting semantic segmentation on landcover satellite imagery through u-net architectures. In Proceedings of the Future Technologies Conference, pages 758–764. Springer, 2022. ↩
-
P. Gudžius, O. Kurasova, V. Darulis, and E. Filatovas. Deep learning based object recognition in multispectral satellite imagery for real-time applications. Machine Vision and Applications, 32(4):98, 2021. ↩
-
M. Hosseini, A. Sevtsuk, F. Miranda, R. M. Cesar Jr, and C. T. Silva. Mapping the walk: A scalable computer vision approach for generating sidewalk network datasets from aerial imagery. Computers, Environment and Urban Systems, 101:101950, 2023. ↩ ↩2 ↩3
-
K. Sun, B. Xiao, D. Liu, and J. Wang. Deep high-resolution representation learning for human pose estimation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019. ↩
-
Z. Zhou, M. M. Rahman Siddiquee, N. Tajbakhsh, and J. Liang. Unet++: A nested u-net architecture for medical image segmentation. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support, pages 3–11. Springer, 2018. ↩
-
F. Isensee, P. F. Jaeger, S. A. Kohl, J. Petersen, and K. H. Maier-Hein. nnu-net: a self-configuring method for deep learning-based biomedical image segmentation. Nature methods, 18(2):203–211, 2021. ↩
-
O. Ronneberger, P. Fischer, and T. Brox. U-net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015. Springer, 2015. ↩
-
A. Hatamizadeh, V. Nath, Y. Tang, D. Yang, H. R. Roth, and D. Xu. Swin unetr: Swin transformers for semantic segmentation of brain tumors in mri images. In International MICCAI Brainlesion Workshop, pages 272–284. Springer, 2021. ↩
-
A. Dosovitskiy et al. An image is worth 16x16 words: Transformers for image recognition at scale. In ICLR, 2021. ↩
-
K. Cha, J. Seo, and T. Lee. A billion-scale foundation model for remote sensing images. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2024. ↩
-
A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y. Lo, et al. Segment anything. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 4015–4026, 2023. ↩ ↩2 ↩3
-
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, et al. Learning transferable visual models from natural language supervision. In International conference on machine learning, pages 8748–8763. PMLR, 2021. ↩
-
Y. Yan, H. Wen, S. Zhong, W. Chen, H. Chen, Q. Wen, R. Zimmermann, and Y. Liang. Urbanclip: Learning text-enhanced urban region profiling with contrastive language-image pretraining from the web. In Proceedings of the ACM on Web Conference 2024, 2024. ↩